1.影响大模型随机生成的参数值
1.1 temperture值:
低(明确答案)<中(无特殊需求为默认)<高(创意需求)
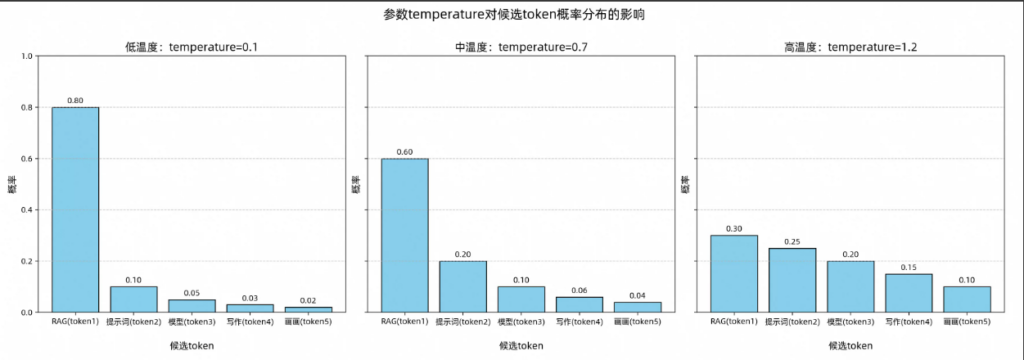
1.2 top_p:
下图展示了不同top_p值对候选Token集合的采样效果。
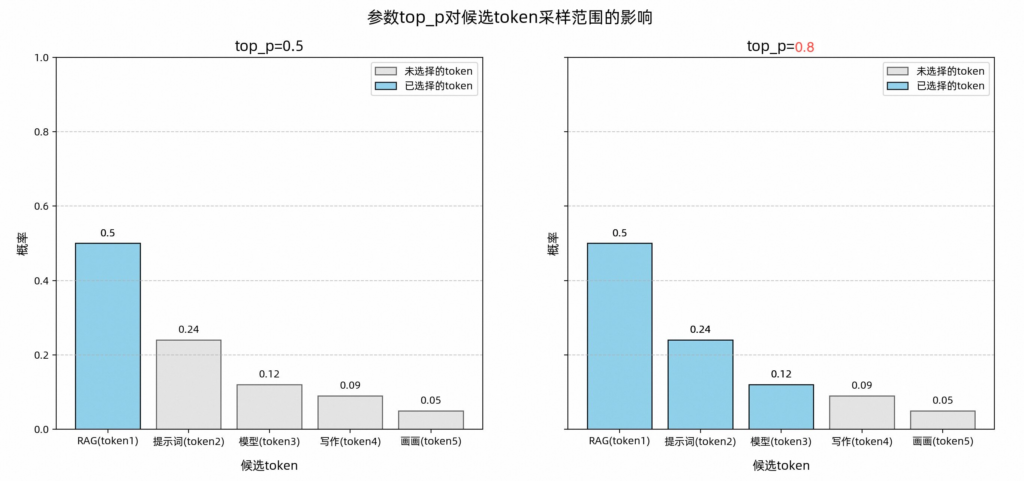
图示中蓝色部分表示累计概率达到top_p阈值(如0.5或0.8)的Token,它们组成新的候选集合;灰色部分则是未被选中的Token。
当top_p=0.5时,模型优先选择最高概率的Token,即“RAG”;而当top_p=0.8时,模型会在“RAG”、“提示词”、“模型”这三个Token中随机选择一个生成输出。
由此可见,top_p值对大模型生成内容的影响可总结为:
- 值越大 :候选范围越广,内容更多样化,适合创意写作、诗歌生成等场景。
- 值越小 :候选范围越窄,输出更稳定,适合新闻初稿、代码生成等需要明确答案的场景。
- 极小值(如 0.0001):理论上模型只选择概率最高的 Token,输出非常稳定。但实际上,由于分布式系统、模型输出的额外调整等因素可能引入的微小随机性,仍无法保证每次输出完全一致。
2.上下文工程解决方案
2.1RAG:
第一阶段:建立索引
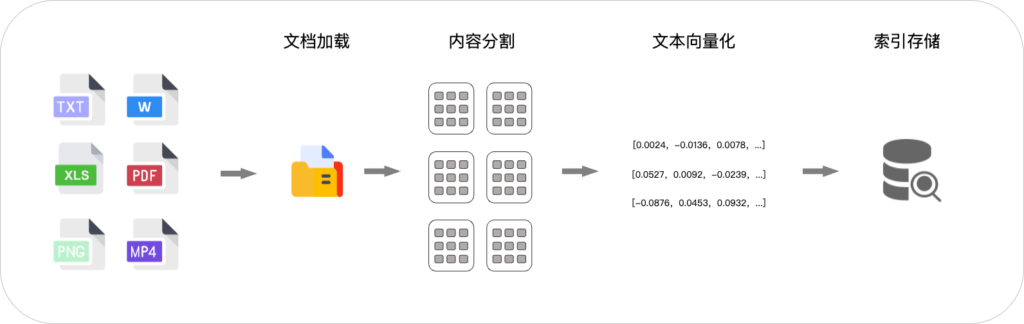
建立索引是为了将私有知识文档或片段转换为可以高效检索的形式。通过将文件内容分割并转化为多维向量(使用专用 Embedding 模型),并结合向量存储保留文本的语义信息,方便进行相似度计算。向量化使得模型能够高效检索和匹配相关内容,特别是在处理大规模知识库时,显著提高了查询的准确性和响应速度。
这些向量经过 Embedding 模型处理后不仅很好地捕捉文本内容的语义信息,而且由于语义已经向量化,标准化,便于之后与检索语义向量进行相关度计算。
第二阶段:检索与生成
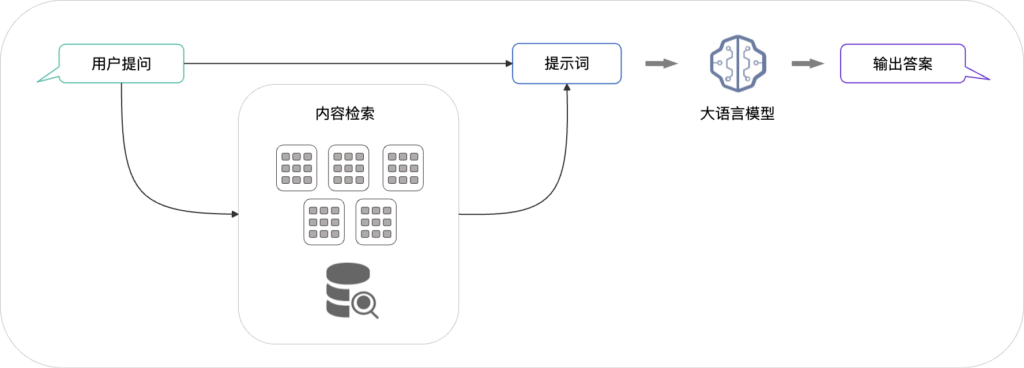
检索生成是根据用户的提问,从索引中检索相关的文档片段,这些片段会与提问一起输入到大模型生成最终的回答。这样大模型就能够回答私有知识问题了。
总的来说,基于 RAG 结构的应用,既避免了将整个参考文档作为背景信息输入而导致的各种问题,又通过检索提取出了与问题最相关的部分,从而提高了大模型输出的准确性与相关性。
2.2RAG工作流程
- 理解了RAG的工作原理一个完整的RAG应用通常包含两个阶段:建立索引与检索生成。建立索引阶段包括文档解析、文本分段、文本向量化、存储索引四个步骤。通过理解RAG的工作原理,你可以更好地对RAG应用进行优化和改进。
- 创建了RAG应用通过LlamaIndex提供的高度集成工具,你快速地创建了一个RAG应用,并学习了如何保存和加载索引。
- 掌握了RAG中的多轮对话你了解了RAG多轮对话面临的独特挑战(检索时上下文丢失),以及业界通用的解决方案(问题改写)。通过LlamaIndex的CondenseQuestionChatEngine,你实现了能够理解对话上下文的RAG应用。
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合了信息检索和生成式模型的技术,能够在生成答案时利用外部知识库中的相关信息。它的工作流程可以分为几个关键步骤:解析与切片、向量存储、检索召回、生成答案等。具体的概念你可以回顾"扩展答疑机器人的知识范围"这一节。
2.2.1建立索引
2.2.1.1文档切片选择方法:
在实际应用中,选择切片方法时不必过于纠结,你可以这样思考:
- 如果你刚开始接触 RAG,建议先使用默认的句子切片方法,它在大多数场景下都能提供不错的效果
- 当你发现检索结果不够理想时,可以尝试:
- 处理长文档且需要保持上下文?试试句子窗口切片
- 文档逻辑性强、内容专业?语义切片可能会有帮助
- 模型总是报 Token 超限?Token 切片可以帮你精确控制
- 处理 Markdown 文档?别忘了有专门的 Markdown 切片
2.2.1.2切片向量化和存储:
2.2.1.2.1选择合适的Embedding
2.2.1.2.2选择合适的向量数据库:内存、本地、云服务向量数据库
选择建议:
- 开发测试时使用内存向量存储
- 小规模应用可以使用本地向量数据库
- 生产环境推荐使用云服务,可根据具体需求选择合适的服务类型
2.2.1.2.3检索召回阶段
检索阶段会遇到的主要问题就是,很难从众多文档切片中,找出和用户问题最相关、且包含正确答案信息的片段。
从切入时机来看,可以将解法分为两大类:
- 在执行检索前,很多用户问题描述是不完整、甚至有歧义的,你需要想办法还原用户真实意图,以便提升检索效果。
- 在执行检索后,你可能会发现存在一些无关的信息,需要想办法减少无关信息,避免干扰下一步的答案生成。
| 时机 | 改进策略 | 示例 |
| 检索前 | 问题改写 | 「附近有好吃的餐厅吗?」=> 「请推荐我附近的几家评价较高的餐厅」 |
| 问题扩写通过增加更多信息,让检索结果更全面 | 「张伟是哪个部门的?」=> 「张伟是哪个部门的?他的联系方式、职责范围、工作目标是什么?」 | |
| 基于用户画像扩展上下文结合用户信息、行为等数据扩写问题 | 内容工程师提问「工作注意事项」=> 「内容工程师有哪些工作注意事项」 项目经理提问「工作注意事项」=> 「项目经理有哪些工作注意事项」 | |
| 提取标签提取标签,用于后续标签过滤+向量相似度检索 | 「内容工程师有哪些工作注意事项」=> 标签过滤:{"岗位": "内容工程师"}向量检索:「内容工程师有哪些工作注意事项」 | |
| 反问用户 | 「工作职责是什么」=> 大模型反问:「请问你想了解哪个岗位的工作职责」 实现反问的提示词可以参考:10分钟构建能主动提问的智能导购 | |
| 思考并规划多次检索 | 「张伟不在,可以找谁」 => 大模型思考规划: => task_1:张伟的职责是什么, task_2:${task_1_result}职责的人有谁 => 按顺序执行多次检索 | |
| ... | ... | |
| 检索后 | 重排序 ReRank + 过滤多数向量数据库会考虑效率,牺牲一定精确度,召回的切片中可能有一些实际相关性不够高 | chunk1、chunk2...、chunk10 => chunk 2、chunk4、chunk5 |
| 滑动窗口检索在检索到一个切片后,补充前后相邻的若干个切片。这样做的原因是:相邻切片之间往往存在语义联系,仅看单个切片可能会丢失重要信息。滑动窗口检索确保了不会因为过度切分而丢失文本间的语义连接。 | 常见的实现是句子滑动窗口,你可以用下方的简化形式来理解: 假设原始文本为:ABCDEFG(每个字母代表一个句子) 当检索到切片:D 补充相邻切片后:BCDEF(前后各取2个切片) 这里的BC和EF是D的上下文。比如: BC可能包含解释D的背景信息EF可能包含D的后续发展或结果这些上下文信息能帮助你更准确地理解D的完整含义通过召回这些相关的上下文切片,你可以提高检索结果的准确性和完整性。 | |
| ... |
2.2.1.2.3.1问题改写
- 使用大模型扩充用户问题
- 将单一查询改写为多步骤查询
- 用假设文档来增强检索(Hyde)
2.2.2.1.3.2提取标签增强检索
在向量检索的基础上,我们还可以添加标签过滤来提升检索精度。这种方式类似于图书馆既有书名检索,又有分类编号系统,能让检索更精准。
标签提取有两个关键场景:
- 建立索引时,从文档切片中提取结构化标签
- 检索时,从用户问题中提取对应的标签进行过滤
2.2.2检索生成
-
- 如果只是简单的信息查询总结,小参数量的模型足以满足需求,比如 qwen-turbo。
- 如果你希望答疑机器人能完成较为复杂的逻辑推理,建议选择参数量更大、推理能力更强的大模型,比如 qwen-plus甚至是 qwen-max。
- 如果你的问题需要查阅大量的文档片段,建议选择上下文长度更大的模型,比如 qwen-long、qwen-turbo或qwen-plus。
- 如果你构建的 RAG 应用面向一些非通用领域,如法律领域,建议使用面向特定领域训练的模型,如farui-plus。
- 充分优化提示词模板,比如:
- 明确要求不编造答案:大模型可能会产生一些不真实的内容,通常称为幻觉。你可以通过提示词要求大模型:「如果所提供的信息不足以回答问题,请明确告知"根据现有信息,我无法回答这个问题。"切勿编造答案。」,来减少大模型产生幻觉的几率。
- 添加内容分隔标记:检索召回的文档切片如果随意混杂在提示词里,人也很难看清整个提示词的结构,大模型也会受到干扰。建议将提示词和检索切片明确地分开,以便大模型能够正确地理解你的意图。
- 根据问题类型调整模板:不同问题的回答范式可能是不同的,你可以借助大模型识别问题类型,然后映射使用不同的提示词模板。比如有些问题,你希望大模型先输出整体框架,然后再输出细节;有些问题你可能希望大模型言简意赅的给出结论。
- 调整大模型的参数,比如:
- 如果你希望大模型输出在相同的问题下,输出的内容尽可能相同,你可以在每次模型调用时传入相同的seed值。
- 如果你希望大模型在回答用户问题时不要总是用重复的句子,你可以适当调高 presence_penalty 值。
- 如果你希望查询事实性的内容,可以适当降低 temperature 或 top_p 值;反之,查询创造性的内容时,可以适当增加它们的值。
- 如果你需要限制字数(如生成摘要、关键词)、控制成本或减少响应时间的场景,可以适当降低max_tokens的值,但是若max_tokens过小,可能会导致输出截断,反之,需要生成大段文本时,可以提高它的值。
- 你也可以查阅千问 API Reference,来了解更多参数的使用说明。
3.适用于推理大模型的提示词技巧
Meta Prompting: 让大模型成为你的提示词教练
一次性就写好一个完美的提示词,往往非常困难。更常见的工作流是:
- 写出第一版提示词。
- 运行它,并分析输出结果中有哪些不符合预期的地方。
- 总结问题,思考如何改进,然后修改提示词。
- 不断重复这个迭代过程,直到满意为止。
技巧一:保持任务提示简洁清晰,提供足够的背景信息
技巧二:避免思维链提示
本节 4.5 中你了解到通过思维链(COT)技术让大模型深入思考提升回复效果。 一般来说,你无需提示推理模型“逐步思考”或“解释你的推理”,因为它们本身会进行深入的思考,你的提示可能反而限制推理模型的发挥。除非你需要大模型严格按照固定的思路去推理,这种情况很少发生。
技巧三:根据模型响应调整提示词
推理模型因其回复形式(包含思考过程),天然适合你分析它的思考推理结论的过程,便于你调整提示词。 因此,你不需要纠结提示词是否足够完善,只需要不断与推理模型对话,过程中补充信息,完善提示词即可。 比如当你的描述太抽象或无法准确描述时,你可以用本节4.4讲到的增加示例的技巧来明确这些信息,这些示例有时可以从与模型的对话历史中挑选出来。 这个过程可以是重复多次的,不断尝试调整提示,让模型不断推理迭代,直到符合你的要求。
+ Code
+ Markdown
技巧四:让推理模型成为你的“提示词教练”
在 4.6 节中,你学习了 Meta Prompting,即让大模型帮助你优化提示词。那么,哪种模型最适合扮演这位“教练”的角色呢?
答案是推理模型。
由于推理模型擅长分步思考和逻辑推导,它们在分析一个提示词的优缺点、并系统性地提出改进建议方面表现得尤为出色。它
4.如何通过 Ragas 对 RAG 应用进行评测。如何通过 Ragas 分数来定位并解决问题
上下文是 RAG 的生命线
- context recall
context recall指标评测的是RAG应用在检索阶段的表现。如果该指标得分较低,你可以尝试从以下方面进行优化:
- 检查知识库
知识库是RAG应用的源头,如果知识库的内容不够完备,则会导致召回的参考信息不充分,从而影响context recall。你可以对比知识库的内容与测试样本,观察知识库的内容是否可以支持每一条测试样本(这个过程你也可以借助大模型来完成)。如果你发现某些测试样本缺少相关知识,则需要对知识库进行补充。
- 更换embedding模型
如果你的知识库内容已经很完备,则可以考虑更换embedding模型。好的embedding模型可以理解文本的深层次语义,如果两句话深层次相关,那么即使“看上去”不相关,也可以获得较高的相似度分数。比如提问是“负责课程研发的是谁?”,知识库对应文本段是“张伟是教研部的成员”,尽管重合的词汇较少,但优秀的embedding模型仍然可以为这两句话打出较高的相似度分数,从而将“张伟是教研部的成员”这一文本段召回。
- query改写
作为开发者,对用户的提问方式做过多要求是不现实的,因此你可能会得到这样缺少信息的问题:“教研部”、“请假”、“项目管理”。如果直接将这样的问题输入RAG应用中,大概率无法召回有效的文本段。你可以通过对员工常见问题的梳理来设计一个prompt模板,使用大模型来改写query,提升召回的准确率。
- context precision
与context recall一样,context precision指标评测的也是RAG应用在检索阶段的表现,但是更注重相关的文本段是否具有靠前的排名。如果该指标得分较低,你可以尝试context recall中的优化措施,并且可以尝试在检索阶段加入rerank(重排序),来提升相关文本段的排名。
- answer correctness
answer correctness指标评测的是RAG系统整体的综合指标。如果该指标得分较低,而前两项分数较高,说明RAG系统在检索阶段表现良好,但是生成阶段出了问题。你可以尝试前边教程学到的方法,如优化prompt、调整大模型生成的超参数(如temperature)等,你也可以更换性能更加强劲的大模型,甚至对大模型进行微调(后边的教程会介绍)等方法来提升生成答案的准确度。
自动化评测流程
在大模型应用开发中,评测应该走在优化前面,而不是"先优化,再评测看效果"。
| 阶段 | 关键动作 | 责任方 |
| 明确业务目标 | 定义可量化的业务指标(如满意度 > 90%) | 业务方/产品 |
| 构建评测集 | 从用户问题抽样,专家编写答案 | 业务专家 |
| 建立自动化评测 | 配置评测框架,获得基线分数 | 技术+业务 |
| 针对性优化 | 根据指标定位问题,实施优化 | 技术+业务 |
| 评测验证 | 对比优化前后效果 | 技术+业务 |
| 持续迭代 | 跟踪意图变化,更新评测集 | 业务专家 |
为什么要"评测先行"?
- 避免盲目优化:没有评测基线,你不知道优化是否真的有效
- 量化改进效果:从"感觉变好了"变成"指标提升了 15%"
- 防止"跷跷板效应":一处优化可能导致另一处退步,评测能发现整体是否提升
5.构建agent完成复杂任务

文章评论